Flink2ES写入性能调优-程序员宅基地
技术标签: Elasticsearch Flink
背景说明
我们线上业务反应使用Flink消费上游kafka topic里的轨迹数据出现backpressure,数据积压严重。单次bulk的写入量为:3000/50mb/30s,并行度为48。针对该问题,为了避免影响线上业务申请了一个与线上集群配置相同的ES集群。本着复现问题进行优化就能解决的思路进行调优测试。
测试环境
- elasticsearch 2.3.3
- flink 1.6.3
- flink-connector-elasticsearch2_2.11
- 八台SSD,56核 :3主5从
Rally分布式压测ES集群
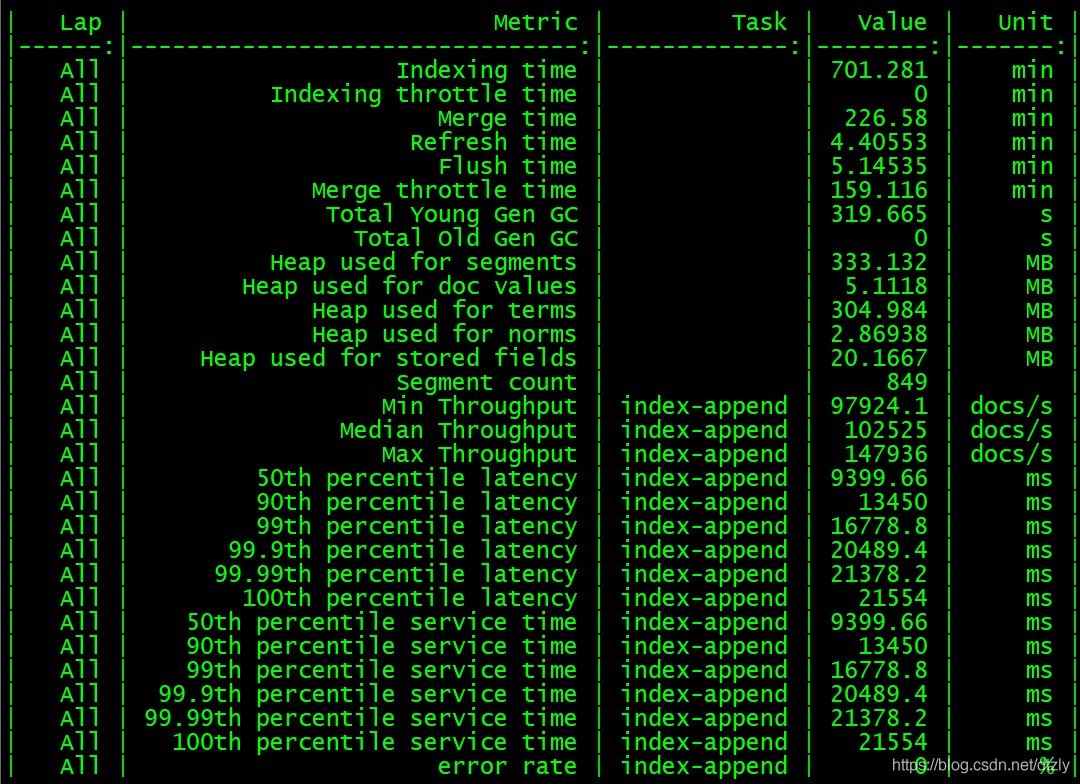
- 从压测结果来看,集群层面的平均写入性能大概在每秒10w+的doc。
Flink写入测试
- 配置文件
config.put("cluster.name", ConfigUtil.getString(ES_CLUSTER_NAME, "flinktest")); config.put("bulk.flush.max.actions", ConfigUtil.getString(ES_BULK_FLUSH_MAX_ACTIONS, "3000")); config.put("bulk.flush.max.size.mb", ConfigUtil.getString(ES_BULK_FLUSH_MAX_SIZE_MB, "50")); config.put("bulk.flush.interval.ms", ConfigUtil.getString(ES_BULK_FLUSH_INTERVAL, "3000")); - 执行代码片段
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
initEnv(env);
Properties properties = ConfigUtil.getProperties(CONFIG_FILE_PATH);
//从kafka中获取轨迹数据
FlinkKafkaConsumer010<String> flinkKafkaConsumer010 =
new FlinkKafkaConsumer010<>(properties.getProperty("topic.name"), new SimpleStringSchema(), properties);
//从checkpoint最新处消费
flinkKafkaConsumer010.setStartFromLatest();
DataStreamSource<String> streamSource = env.addSource(flinkKafkaConsumer010);
//Sink2ES
streamSource.map(s -> JSONObject.parseObject(s, Trajectory.class))
.addSink(EsSinkFactory.createSinkFunction(new TrajectoryDetailEsSinkFunction())).name("esSink");
env.execute("flinktest");
- 运行时配置
任务容器数为24个container,一共48个并发。savepoint为15分钟
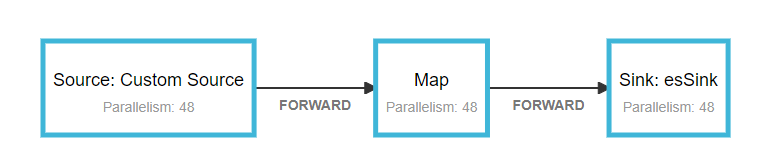
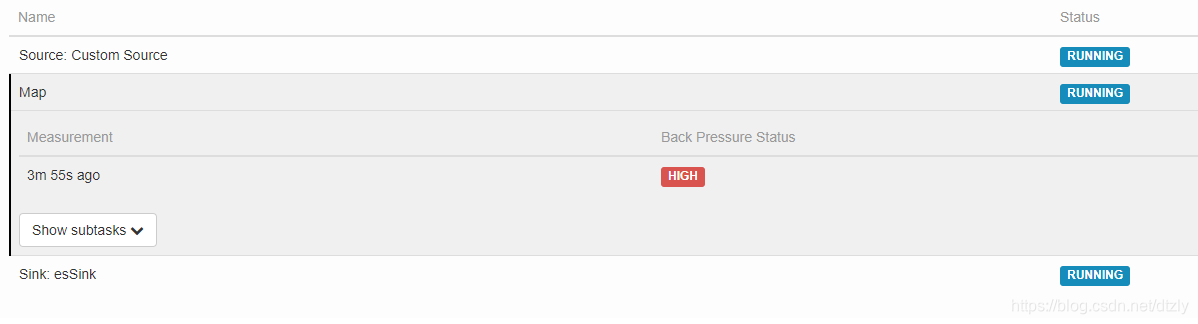
- 运行现象
- source和Map算子均出现较高的反压
- ES集群层面,目标索引写入速度写入陡降
平均QPS为:12k左右
- 对比取消sink算子后的QPS
streamSource.map(s -> JSONObject.parseObject(s, FurionContext.class)).name("withnosink"); - source和Map算子均出现较高的反压
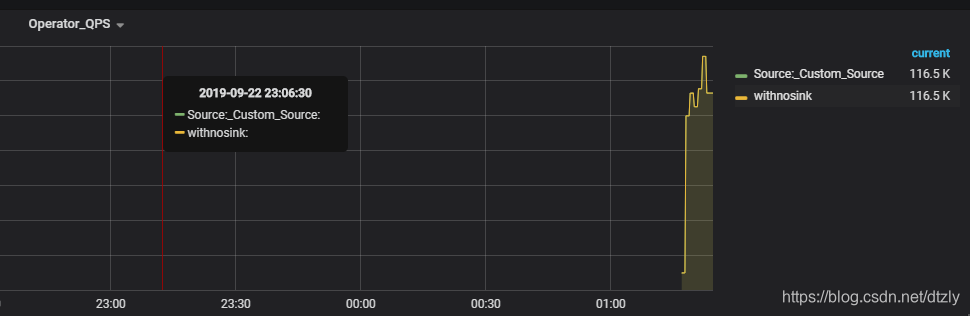
平均QPS为:116k左右
有无sink参照实验的结论
取消sink2ES的操作后,QPS达到110k,是之前QPS的十倍。由此可以基本判定: ES集群写性能导致的上游反压
优化方向
-
索引字段类型调整
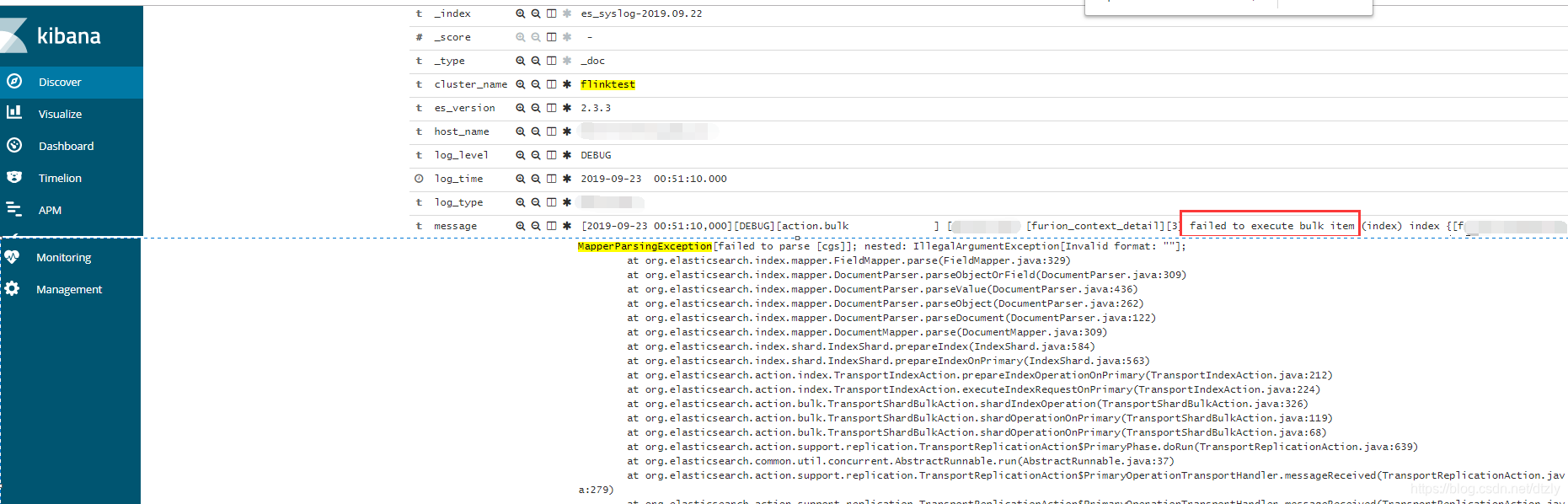
bulk失败的原因是由于集群dynamic mapping自动监测,部分字段格式被识别为日期格式而遇到空字符串无法解析报错。
解决方案:关闭索引自动检测
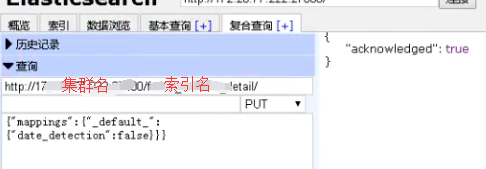
效果:
ES集群写入性能明显提高但flink operator 依然存在反压: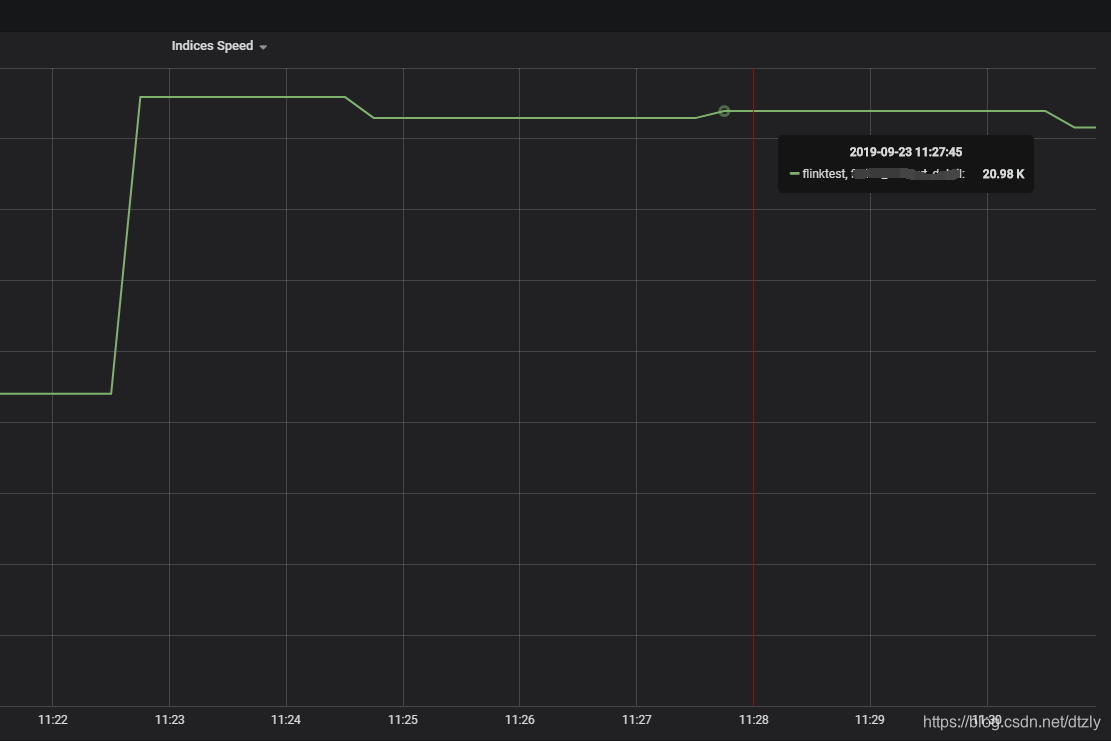
-
降低副本数
curl -XPUT{集群地址}/{索引名称}/_settings?timeout=3m -H "Content-Type: application/json" -d'{"number_of_replicas":"0"}'
- 提高refresh_interval
针对这种ToB、日志型、实时性要求不高的场景,我们不需要查询的实时性,通过加大甚至关闭refresh_interval的参数提高写入性能。
curl -XPUT{集群地址}/{索引名称}/_settings?timeout=3m -H "Content-Type: application/json" -d '{ "settings": { "index": {"refresh_interval" : -1 } } }'
- 检查集群各个节点CPU核数
在flink执行时,通过Grafana观测各个节点CPU 使用率以及通过linux命令查看各个节点CPU核数。发现CPU使用率高的节点CPU核数比其余节点少。为了排除这个短板效应,我们将在这个节点中的索引shard移动到CPU核数多的节点。
curl -XPOST {集群地址}/_cluster/reroute -d'{"commands":[{"move":{"index":"{索引名称}","shard":5,"from_node":"源node名称","to_node":"目标node名称"}}]}' -H "Content-Type:application/json"
以上优化的效果:
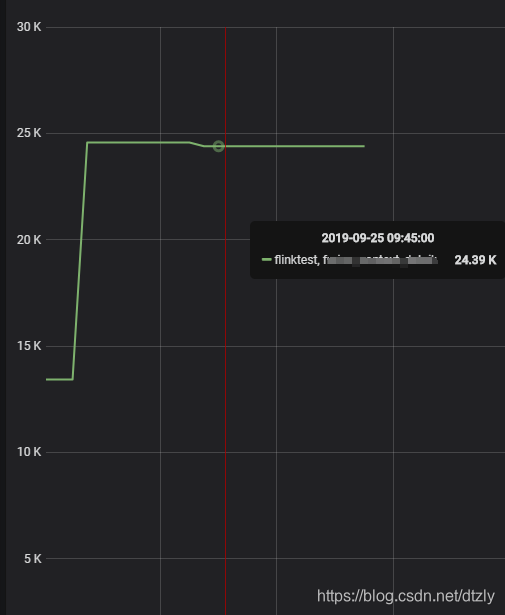
经过以上的优化,我们发现写入性能提升有限。因此,需要深入查看写入的瓶颈点
- 在CPU使用率高的节点使用Arthas观察线程:
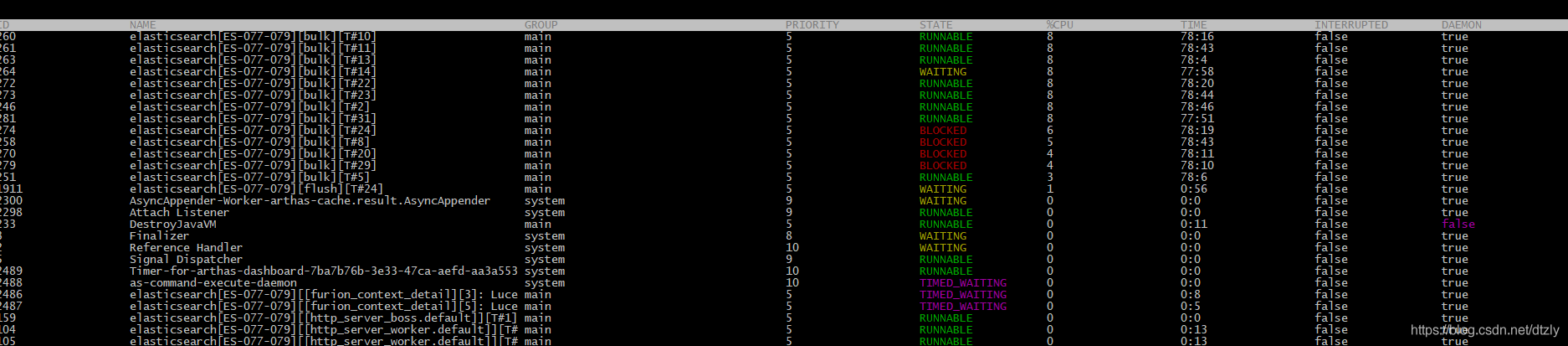
- 打印阻塞的线程堆栈
"elasticsearch[ES-077-079][bulk][T#3]" Id=247 WAITING on java.util.concurrent.LinkedTransferQueue@369223fa
at sun.misc.Unsafe.park(Native Method)
- waiting on java.util.concurrent.LinkedTransferQueue@369223fa
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.LinkedTransferQueue.awaitMatch(LinkedTransferQueue.java:737)
at java.util.concurrent.LinkedTransferQueue.xfer(LinkedTransferQueue.java:647)
at java.util.concurrent.LinkedTransferQueue.take(LinkedTransferQueue.java:1269)
at org.elasticsearch.common.util.concurrent.SizeBlockingQueue.take(SizeBlockingQueue.java:161)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
从上面的线程堆栈我们可以看出线程处于等待状态。
关于这个问题的讨论详情查看此链接,这个issue讨论大致意思是:节点数不够,需要增加节点。于是我们又增加节点并通过设置索引级别的total_shards_per_node参数将索引shard的写入平均到各个节点上)
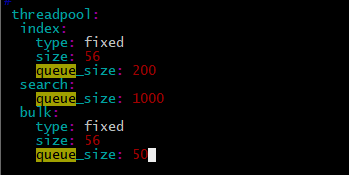
- 线程队列优化
ES是将不同种类的操作(index、search…)交由不同的线程池执行,主要的线程池有三:index、search和bulk thread_pool。线程池队列长度配置按照官网默认值,我觉得增加队列长度而集群本身没有很高的处理能力线程还是会await(事实上实验结果也是如此在此不必赘述),因为实验节点机器是56核,对照官网,:
因此修改size数值为56。
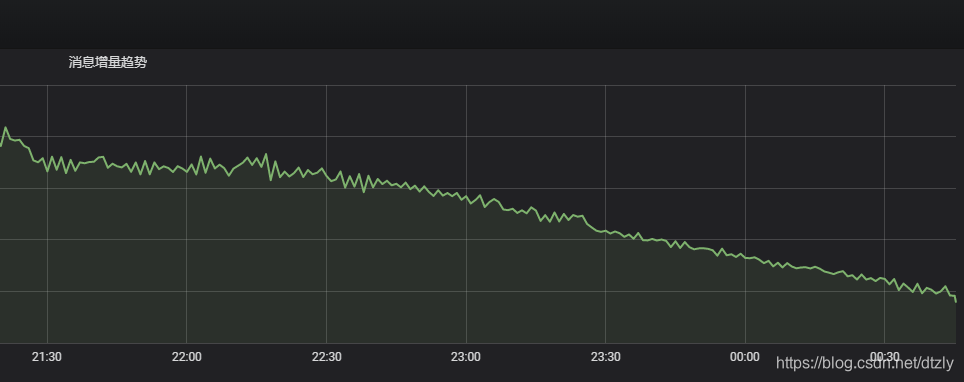
经过以上的优化,我们发现在kafka中的topic积压有明显变少的趋势:
- index buffer size的优化
参照官网:

indices.memory.index_buffer_size : 10%
- translog优化:
索引写入ES的基本流程是:1.数据写入buffer缓冲和translog 2.每秒buffer的数据生成segment并进入内存,此时segment被打开并供search使用查询 3.buffer清空并重复上述步骤 4.buffer不断
添加、清空translog不断累加,当达到某些条件触发commit操作,刷到磁盘。es默认的刷盘操作为request但容易部分操作比较耗时,在日志型集群、允许数据在刷盘过程中少量丢失可以改成异步async
另外一次commit操作是在translog达到某个阈值执行的,可以把大小(flush_threshold_size )调大,刷新间隔调大。
index.translog.durability : async
index.translog.flush_threshold_size : 1gb
index.translog.sync_interval : 30s
效果:
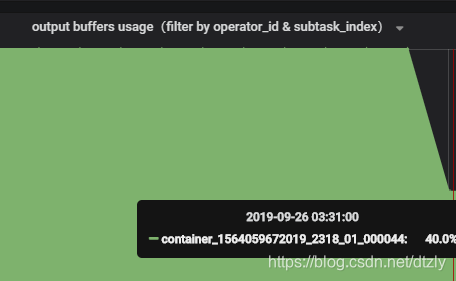
- flink反压从打满100%降到40%(output buffer usage):
- kafka 消费组里的积压明显减少:
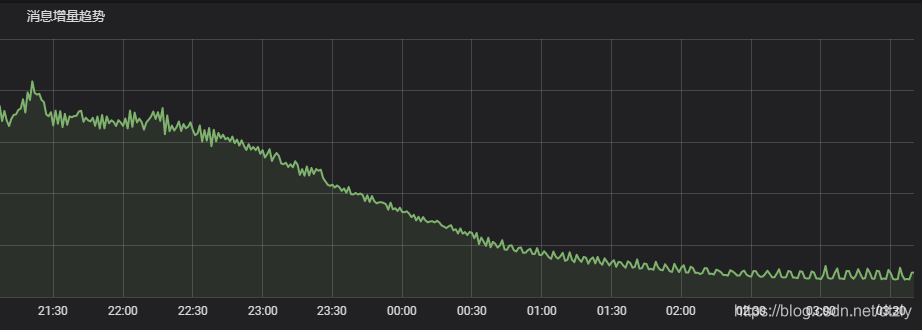
总结
当ES写入性能遇到瓶颈时,我总结的思路应该是这样:
- 看日志,是否有字段类型不匹配,是否有脏数据。
- 看CPU使用情况,集群是否异构
- 客户端是怎样的配置?使用的bulk 还是单条插入
- 查看线程堆栈,查看耗时最久的方法调用
- 确定集群类型:ToB还是ToC,是否允许有少量数据丢失?
- 针对ToB等实时性不高的集群减少副本增加刷新时间
- index buffer优化 translog优化,滚动重启集群
智能推荐
Linux安装Oracle 19c_linux安装oracle19c-程序员宅基地
文章浏览阅读1.3w次,点赞8次,收藏83次。1.在root目录下,执行命令yum -y localinstall oracle-database-preinstall-19c-1.0-1.el7.x86_64.rpm,进行Oracle19c的预安装,等待安装完成。2.在root目录下,执行命令yum -y localinstall oracle-database-ee-19c-1.0-1.x86_64.rpm,输入数据库语句确认数据库语句可以正常执行,1.下载安装包oracle-database-ee-19c-1.0-1.x86_64.rpm。_linux安装oracle19c
程序流程控制_什么是改流程不改代码-程序员宅基地
文章浏览阅读587次。程序流程控制流程控制语句是用来控制程序中各语句执行顺序的语句,可以把语句组合成能完成一定功能的小逻辑模块。其流程控制方式采用结构化程序设计中规定的三种基本流程结构,即:顺序结构分支结构循环结构顺序结构程序从上到下逐行地执行,中间没有任何判断和跳转。分支结构根据条件,选择性地执行某段代码。有if…else和switch-case两种分支语句。循环结构根据循环条件,重复性的执行某段代码。有while、do…while、for三种循环语句。注:JDK1.5提供了foreach_什么是改流程不改代码
Win API Functions in Alphabetical Order - API 函数 字母排序 参考 - English - From MSDN - HackerJLY_using three consecutive letters in alphabetical or-程序员宅基地
文章浏览阅读1k次。_using three consecutive letters in alphabetical order
js-瀑布流代码-程序员宅基地
文章浏览阅读176次。2019独角兽企业重金招聘Python工程师标准>>> ..._js瀑布流效果代码
CANoe14.0新增这些超实用小功能:主要窗口 | Panel Designer | Option CAN | Option LIN | Option Ethernet | Option J1939_canoe有哪些功能-程序员宅基地
文章浏览阅读2.4k次。CANoe是集单个ECU和整车ECU网络开发、测试和分析功能于一体的综合软件工具。由于其强大的功能,广泛的被OEM和供应商的网络设计工程师、开发和测试工程师所应用,如应用CANoe.Car2x进行C-V2X仿真测试、应用CANoe和vTESTstudio完成TC8车载以太网一致性测试、基于CANoe实现诊断Coding及Flash等,很好地帮助工程师们完成从系统设计到测试的整个开发过程。目前CANoe14.0版本已经发布一段时间了,其中增加了很多新功能,在Vector中国的微信公众号中已经对主要新功能._canoe有哪些功能
好程序员Java教程分享Java必学MySQL数据库应用场景_java开发加mysql字段场景-程序员宅基地
文章浏览阅读159次。 好程序员Java教程分享Java必学之MySQL数据库应用场景,在当前的后台开发中,MySQL应用非常普遍,企业在选拔Java人才时也会考察求职者诸如性能优化、高可用性、备份、集群、负载均衡、读写分离等问题。想要成为高薪Java工程师,一定要熟练掌握MySQL,接下来好程序员Java教程小编就给大家分享MySQL数据库应用场景知识。1、单Master单Master的情况是普遍存在的,对..._java开发加mysql字段场景
随便推点
51单片机如何用c语言位定义,嵌入式编程(一):51单片机如何将函数 定义到指定程序地址...-程序员宅基地
文章浏览阅读694次。在单片机编程使用中,会涉及到将某些函数定义到指定的code区。此时需要对工程文件进行配置修改才可完成。本期针对单片机平台做出说明介绍1、测试目标将函数testaddr定义到0x6000地址2、测试环境LKT4106加密芯片算法工程、KEIL-C51编译软件、3、实现步骤3.1 使用KEIL软件导入LKT4106算法工程(KEIL软件基本操作不再敷述,如不清楚请自行百度)3.2 在App_Main...._keil c51 位定义
小程序修改原生标题栏返回键的方法-程序员宅基地
文章浏览阅读700次。在开发的过程中,我遇到过一个需求,需要将4到5个页面合为一个,在页面里制作切换和返回方法,我想使用原生的标题,这个时候就面临着一个问题,返回方法怎么办,原生标题的返回方法无法监听到,那么将制作返回功能。解决方法:在小程序的生命周期中,有这么一个周期 /** * 生命周期函数--监听页面卸载 */ onUnload: function () { },这里..._原生小程序的返回按钮
机器学习算法四之SVM支持向量机原理详解-程序员宅基地
文章浏览阅读3.7k次。支持向量机SVM(Support Vector Machine)1.解决问题思路展开*要解决的问题:什么样的决策边界才是最好的?*特征数据本身如果就很难分,该怎么办?*计算负责度怎么样?能否实际应用?==>目标:基于上述问题对SVM进行推导1.1决策边界右图中的决策边界更具容忍度,更加可靠1.2 通过距离获得决策边界(求取点到面的距离)通过平面上两点可以得到平面的法向量,进而获得与法相量平行的单位方向向量,通过平面外一点X到平面上一点x’的距离D在单位方向向量的投影可以求出距离d_svm支持向量机原理
spatialreg | 空间滞后模型(SLR)、空间误差模型(SEM)和空间杜宾模型(SDM)的简单形式的R语言实现...-程序员宅基地
文章浏览阅读1.5w次,点赞8次,收藏108次。关于空间计量模型,小编是通过阅读勒沙杰(James LeSage)和佩斯(R.Kelley Pace)合著的《空间计量经济学导论》(Introduction of Spatial Econ..._spatial auto regression与slm
c/c++初学者用什么软件比较好_c++初学者软件-程序员宅基地
文章浏览阅读2.2w次,点赞22次,收藏55次。工欲善其事,必先利其器。在编程领域里,每个人都会有他/她的入门语言,各持己见。很重要的一点是现今的各种编程语言,或多或少都是 C 语言的衍生品,或者是衍生品的衍生品。语言相通,只要 C 语言学好了,上手其他语言问题不大。C 语言的灵魂在于指针,指针可以帮助你更好的理解内存,理解操作系统的工作机理,C++ 就是 C 的衍生品之一,兼容 C 语言。_c++初学者软件
【开发问题】-数据库连接池超时-“Unable to acquire JDBC Connection“-程序员宅基地
文章浏览阅读2.8w次。项目描述:基于Springboot-2.3.7.RELEASE问题描述:1、完成接口开发后,默认启动hikari连接池,配置默认2、完成测试环境的部署3、接口调用超过一定次数或者频率过高,服务报错 Unable to acquire JDBC Connection问题分析:通过分析整体服务的日志,发现错误提示是突然的,在本地通过jmeter进行压测,线程数超过Hikari默认连接数后服务会超时响应,在调整连接池参数,优化sql查询等等方法后仍然会出现该问题,查看mysql_unable to acquire jdbc connection