MTCNN 论文学习_mtcnn算法论文-程序员宅基地
Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Network
论文地址:https://arxiv.org/ftp/arxiv/papers/1604/1604.02878.pdf
Abstract
在无条件约束的环境下进行人脸检测和对齐是非常具挑战性的,因为你要考虑不同的姿势,光照,和遮挡。最近的研究显示,深度学习方法能在这两个任务上获得不错的效果。这篇论文提出了一个深度级联多任务框架,探索它们内在的关系,进而提升表现。此框架采取了一个级联架构,包含三个阶段的深度卷积网络由粗到细地来预测人脸和特征点位置。此外,在学习过程中,我们提出一个新的 online hard example mining 策略,可以自动提升表现,而不需人工选取样本。此方法在 人脸检测的 FDDB 和WIDER FACE benchmarks 上获得了 state of art 的成绩,在人脸对齐的 AFLW benchmark 上也表现不俗。
1. Introduction
人脸检测和对齐对于人脸应用至关重要,如人脸识别和表情分析。但是,面部在视觉呈现上的差异,如遮挡,姿势变化,和极端光照,给现实世界中的人脸应用带来了巨大的挑战。
Viola 与 Jones 提出了一个级联人脸检测器,它利用 Haar 特征和 AdaBoost 来训练一个级联分类器,获得了不错的表现。但是一些实验表明这个检测器在实际应用中效果会下降很多,当人脸的视觉变化很大时。另有一些论文介绍了 deformable part models (DPM) 用于人脸检测,表现优异。但是它们都需要很高的算力,而且在训练阶段需要很多的标注数据。Yang et al. 提出了用于人脸属性识别的深度卷积网络,以获取人脸区域的高响应,然后进一步产生人脸候选框。但是,由于 CNN 结构复杂,在实际应用中很费时。Li et al. 利用级联 CNNs 来识别人脸,但是需要候选框校准,这带来了额外的计算成本,而且忽略了人脸关键点位置和边框回归中的内在关联。
人脸对齐也受到了很大的关注。基于回归的模型与 template fitting approaches 是两个主要的方向。最近,Zhang et al. 提出利用人脸属性识别作为辅助,使用 CNN 来增强人脸对齐表现的方法。
但是,绝大多数的人脸检测和对齐方法都忽略了这两个任务之间的内在联系。尽管有些工作试图去共同解决这俩问题,但是效果有限。例如,Chen et al. 利用随机森林和像素值差异,来共同进行对齐和检测任务。但是,人为选取的特征限制了它的效果。Zhang et al. 使用多任务 CNN 来提升 multi-view 的人脸检测准确率,但是初始检测窗口是由一个弱人脸检测器产生,因而检测精度有限。
另一方面,训练过程中的 mining hard samples 对增强检测器的效果至关重要。但是传统的 hard sample mining 通常是 offline 的方式操作,这就需要更多的人为操作。所以,针对人脸检测和对齐设计一个 online hard sample mining 方法就变得非常迫切,它能自动地适应当前训练过程。
这篇论文中,我们提出了一个新的框架,利用级联 CNNs 整合检测和对齐的任务。它主要包含3个阶段。第一阶段,快速地通过一个较浅的 CNN 来产生候选窗口。然后,通过一个复杂点的 CNN 来优化候选窗口,剔除那些不包含人脸的窗口。最终,使用一个更复杂的 CNN 来优化结果,输出人脸关键点位置。该多任务学习框架能显著地提升了算法的表现。这篇论文的主要贡献如下:
- 提出了一个新的级联 CNNs 框架,共同进行人脸检测和对齐;
- 提出了一个高效的方法来进行 online hard sample mining 来提升表现;
- 在 benchmarks 上进行充分的实验,与目前 state of art 的方法进行比较。
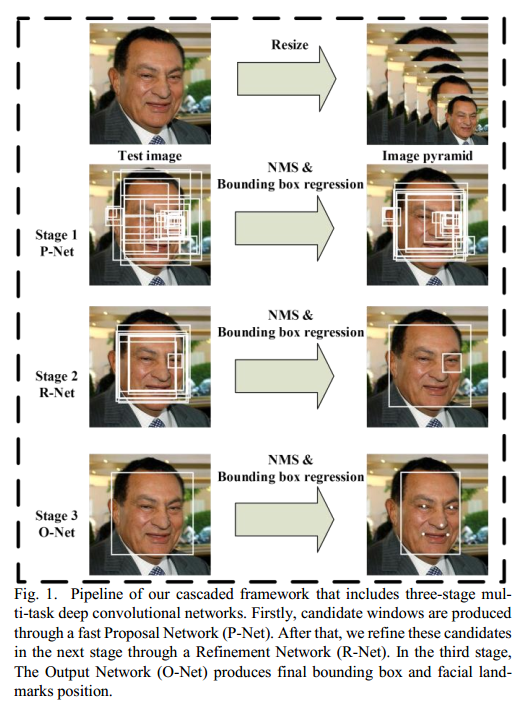
2. Approach
A. Overall Framework
我们的方法流程如图1中所示。给定一张图片,我们首先将它的大小调整为不同的比例,产生图像金字塔,然后将该图像金字塔作为“3-阶段级联框架”的输入:
阶段一:我们使用了一个全卷积网络,叫 Proposal Network (P-Net),来获取候选框,以及它们的边框回归向量。然后用估计的边框回归向量来校准这些候选框。然后,用非最大抑制(non-maximum suppression, NMS)来合并高度重合的候选框。
阶段二:将所有的候选框输入进另一个 CNN,叫 Refine Network (R-Net),它进一步剔除那些假的候选框,对边框回归进行校准,然后用 NMS 来合并重合的候选框。
阶段三:它与阶段二类似,但是在这一步我们的目的是获得人脸更多的细节。尤其是,网络将输出人脸的关键点位置。
B. CNN Architecture
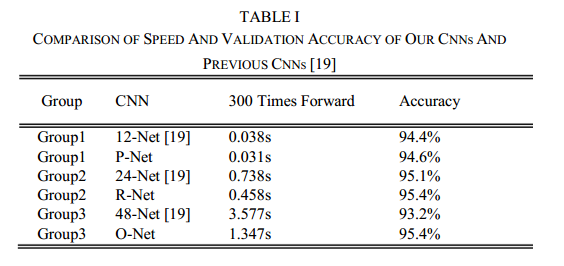
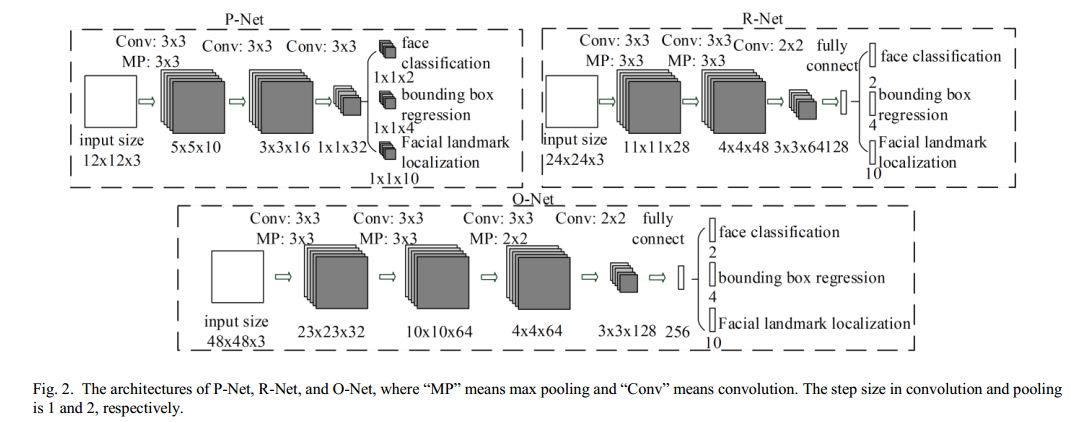
在论文“A convolutional neural network cascade for face detection” 中,作者设计了多个 CNNs 来进行人脸检测。但是,我们注意到,它的表现受以下几方面限制:(1)一些滤波器缺乏权值的多样性,这限制了它们去产生 discriminative 信息;(2)与其它多类别目标检测和分类任务相比,人脸检测是一个二元分类任务,所以它需要的滤波器数量就比较少,但是这些滤波器的判别能力要强。所以,作者就降低了滤波器的个数,将 5 × 5 5\times 5 5×5的滤波器改为 3 × 3 3\times 3 3×3的滤波器,降低计算量,增加网络深度,这样来提升性能。有了这些改善,我们就能获得更优的检测效果,运行时间更短。
C. Training
我们使用3个任务来训练我们的 CNN 检测器:有人脸/没人脸分类,边框回归,人脸关键点定位。
- 人脸分类:学习目标就是一个两类别的分类任务。对每个样本 x i x_i xi,我们使用交叉熵损失函数:
L i d e t = − ( y i d e t l o g ( p i ) ) + ( 1 − y i d e t ) ( 1 − l o g ( p i ) ) ( 1 ) L_i^{det} = -(y_i^{det} log(p_i)) + (1-y_i^{det})(1-log(p_i))\quad \quad \quad (1) Lidet=−(yidetlog(pi))+(1−yidet)(1−log(pi))(1)
p i p_i pi是网络输出的,一个样本是否是人脸的概率。 y i d e ∈ { 0 , 1 } y_i^{de} \in \{0,1\} yide∈{ 0,1}表示 ground-truth 标签。
- 边框回归:对每个候选框,我们预测它和最近的 ground truth 边框(ground truth 边框的左上角位置,高度和宽度)的偏移量。学习目标是一个回归问题,我们对每个样本 x i x_i xi使用欧式损失:
L i b o x = ∣ ∣ y ^ i b o x − y i b o x ∣ ∣ 2 2 ( 2 ) L_i^{box} = ||\hat y_i^{box} - y_i^{box}||^2_2 \quad \quad \quad (2) Libox=∣∣y^ibox−yibox∣∣22(2)
y ^ i b o x \hat y_i^{box} y^ibox 是从网络中获得的回归值,而 y i b o x y_i^{box} yibox 是ground truth 坐标。有4个坐标,包括左上角位置,高度和宽度,因此 y i b o x ∈ R 4 y_i^{box} \in \mathbb{R}^4 yibox∈R4。
- 人脸关键点定位:与边框回归任务类似,人脸关键点检测也被看作一个回归问题,我们最小化欧式损失:
L i l a n d m a r k = ∣ ∣ y ^ i l a n d m a r k − y i l a n d m a r k ∣ ∣ 2 2 ( 3 ) L_i^{landmark} = ||\hat y_i^{landmark} - y_i^{landmark}||^2_2\quad \quad \quad (3) Lilandmark=∣∣y^ilandmark−yilandmark∣∣22(3)
y ^ i l a n d m a r k \hat y_i^{landmark} y^ilandmark是人脸关键点的坐标,从网络中计算得来; y i l a n d m a r k y_i^{landmark} yilandmark 是 ground truth 坐标。有5个关键点,包括左眼,右眼,鼻子,左嘴角,和右嘴角,所以 y i l a n d m a r k ∈ R 1 0 y_i^{landmark}\in \mathbb{R}^10 yilandmark∈R10。
- 多源训练:因为我们在每个 CNN 里要做不同的任务,就要有不同类别的训练图像,如人脸,没人脸,部分对齐的人脸。这样,前面的一些损失函数就没有使用。例如,对背景区域的样本,我们只计算 L i d e t L_i^{det} Lidet,其它两个损失函数都设为0。我们只需要一个样本类型表示器就可以做到。这样,整个学习目标如下:
m i n ∑ i = 1 N ∑ j ∈ { d e t , b o x , l a n d m a r k } α j β i j L i j ( 4 ) min \sum_{i=1}^N \sum_{j\in \{det,box,landmark\}} \alpha_j \beta_i^j L_i^j \quad \quad \quad (4) mini=1∑Nj∈{ det,box,landmark}∑αjβijLij(4)
N N N是训练样本的个数, α j \alpha_j αj表示任务的重要程度。我们在 P-Net 和 R-Net 中使用 α d e t = 1 , α b o x = 0.5 , α l a n d m a r k = 0.5 \alpha_{det}=1, \alpha_{box}=0.5, \alpha_{landmark}=0.5 αdet=1,αbox=0.5,αlandmark=0.5,在 O-Net 中使用 α d e t = 1 , α b o x = 0.5 , α l a n d m a r k = 1 \alpha_{det}=1, \alpha_{box}=0.5, \alpha_{landmark}=1 αdet=1,αbox=0.5,αlandmark=1 来更精准地获取人脸关键点位置。 β i j ∈ { 0 , 1 } \beta_i^j \in \{0,1\} βij∈{ 0,1}是样本类型表示器。这样,我们很自然地就会去选择随机梯度下降法来训练 CNNs。
- Online hard example mining:与传统方法的在分类器训练后进行 hard sample mining 不同,我们在人脸分类任务中就进行 online hard example mining,让它自动地适应训练过程。
在每个 mini-batch 中,我们对前向传播中得到的损失值进行排序,选择最高的 70 % 70\% 70% 作为 hard samples。然后在反向传播时,我们只计算 hard samples 中的梯度。意思就是,在训练过程中我们忽略容易掉样本,因为它们对提升检测器没有太多帮助。实验表明,这个训练策略能产生更好的表现,而不需要人为的样本选择。
3. Experiments
Pls read paper for more details.
智能推荐
树莓派python学习篇 (二)红外避障传感器_红外避障传感器代码-程序员宅基地
文章浏览阅读4k次,点赞4次,收藏42次。一、红外避障传感器介绍红外避障传感器是专为轮式机器人设计的一款距离可调式避障传感器。其具有一对红外线发射与接收管,发射管发射出一定频率的红外线,当检测方向遇到障碍物(反射面)时,红外线反射回来被接收管接收,此时指示灯亮起,经过电路处理后,信号输出接口输出数字信号,可通过电位器旋钮调节检测距离,有效距离2~40cm,工作电压为3.3V-5V,由于工作电压范围宽泛,在电源电压波动比较大的情况下仍能稳定工作,适合多种单片机、Arduino控制器、树莓派使用,安装到机器人上即可感测周围环境的变化。二、规格参数_红外避障传感器代码
入门学C语言的基础,必备的20个经典程序。(C语言必看的20个经典程序)_c语言程序-程序员宅基地
文章浏览阅读894次,点赞4次,收藏9次。j += gap) { //对步长为gap的元素进行直插排序,当gap为1时,就是直插排序。gap /= 2) { // 步长初始化为数组长度的一半,每次遍历后步长减半,void bubbleSort( int data[] ,int n )//data[]是传过来的数组,n是数组中那些数的个数。if (right <= 0 && left == 1)//排除第一个单词只有一个字母的情况。for (i = 0;if(data[j]>data[j+1])//判断如果左边的数大于右边的数,就把大的数往右移。_c语言程序
【物联网】探索NE555:一款经典的集成电路(超详细)-程序员宅基地
文章浏览阅读362次,点赞3次,收藏5次。NE555是一种集成电路,其内部结构包括比较器、RS触发器、电压比较器和输出级三个主要功能模块,外部引脚则提供了与其他电路元件进行连接的接口。NE555的设计目的是为了提供一种简单方便的定时器解决方案,它广泛应用于模拟和数字电路中。你的支持,我的动力;祝各位前程似锦,offer不断,步步高升!!!” />你的支持,我的动力;祝各位前程似锦,offer不断,步步高升!!!更多资料点击此处获qu!!
Linux中的高级IO(非阻塞IO与阻塞式IO,多路IO复用,异步IO)_非阻塞io和多路io复用阻塞速度(1)-程序员宅基地
文章浏览阅读856次,点赞10次,收藏10次。你的支持,我的动力;祝各位前程似锦,offer不断,步步高升!!!、讲解视频,并且后续会持续更新**如果你觉得这些内容对你有帮助,可以+V:Vip1104z获取!!!(备注:嵌入式)你的支持,我的动力;祝各位前程似锦,offer不断,步步高升!!!更多资料点击此处获qu!!
C++通过学生类统计学生各种信息-程序员宅基地
文章浏览阅读1.4k次,点赞2次,收藏9次。C++通过学生类统计学生各种信息
《笨办法学python》习题31-35_32.if a = [1,2,3,4,5; 3,4,5,6,7], then the value o-程序员宅基地
文章浏览阅读183次。习题31:作出决定代码print("""You enter a dark room with two doors.Do you go through door #1 or door #2?""")door = input(">")if door == "1": print("There's a giant bear here eating a cheese cake.") print("What do you da?") print("1.Take the cak_32.if a = [1,2,3,4,5; 3,4,5,6,7], then the value of min (max (a)) is___3__.
随便推点
SpringBoot项目扫描不到其他SpringBoot项目jar包下类的问题(maven插件导致)_springboot扫描不到其他模块的包(1)-程序员宅基地
文章浏览阅读655次,点赞6次,收藏14次。然后在另一个Application中的pom.xml引入了相应依赖(比如是test-a.jar),但是SpringBoot程序启动时找不到test-a.jar中的所有类。但是可以找到其他依赖jar包的类。事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!通过对比结果发现:扫描不到的jar包是使用SpringBoot的maven插件打的包。
【k8s】【Prometheus】_prometheus导入json-程序员宅基地
文章浏览阅读1.1k次。【代码】【k8s】【Prometheus】【待写】_prometheus导入json
DES加密解密-程序员宅基地
文章浏览阅读862次,点赞26次,收藏18次。Toast.makeText(mContext, “请输入加密内容”, Toast.LENGTH_SHORT).show();Toast.makeText(mContext, “请先加密”, Toast.LENGTH_SHORT).show();//初始化向量参数,AES 为16bytes. DES 为8bytes,只能8位。case R.id.btn_encryption://加密。@param key 加密私钥,长度不能够小于8位。@param key 加密私钥,长度不能够小于8位。
Eclipse格式化代码默认长度_eclipse 格式化代码长度设置-程序员宅基地
文章浏览阅读1.8k次。eclipse 默认设置的换行长度, 格式化代码后,同一个方法里面参数也经常被,换行,非常难看。方法/步骤1.Java代码打开Eclipse的Window菜单,然后Preferences->Java->Code Style->Formatter->Edit ->Line Wrapping->Maximum line width:默认80加个0,改成200就行了。2._eclipse 格式化代码长度设置
获取接口所有实现类的三种方式:Spring的ListableBeanFactory容器的getBeanNamesForType方法、利用Reflections工具进行反射扫描、使用SPI-程序员宅基地
文章浏览阅读3.9k次。前言在策略模式应用中,需要获取到策略接口的所有实现类,本文记录三种获取某接口所有实现类的方法,分别是利用Spring的ListableBeanFactory容器的getBeanNamesForType方法,利用Reflections工具进行反射扫描、利用SPI方式。1、借助于Spring容器2、反射扫描3、SPI...
LLM 推理优化探微 (3) :如何有效控制 KV 缓存的内存占用,优化推理速度?-程序员宅基地
文章浏览阅读1.1k次,点赞11次,收藏27次。本文主要内容如下:(1) KV缓存随序列长度线性增长,容易超过模型本身的规模,严重制约最大序列长度; (2) 减小KV缓存对GPU内存的占用,是优化推理速度和吞吐量的关键; (3) MQA、GQA等新型注意力机制、FastGen等缓存压缩策略,以及PagedAttention等内存管理机制,都是能够有效缓解 KV 缓存内存占用压力的技术手段。