《数据结构》— 线段树知识点模版详解_线段树考点-程序员宅基地
线段树详解
第一部分
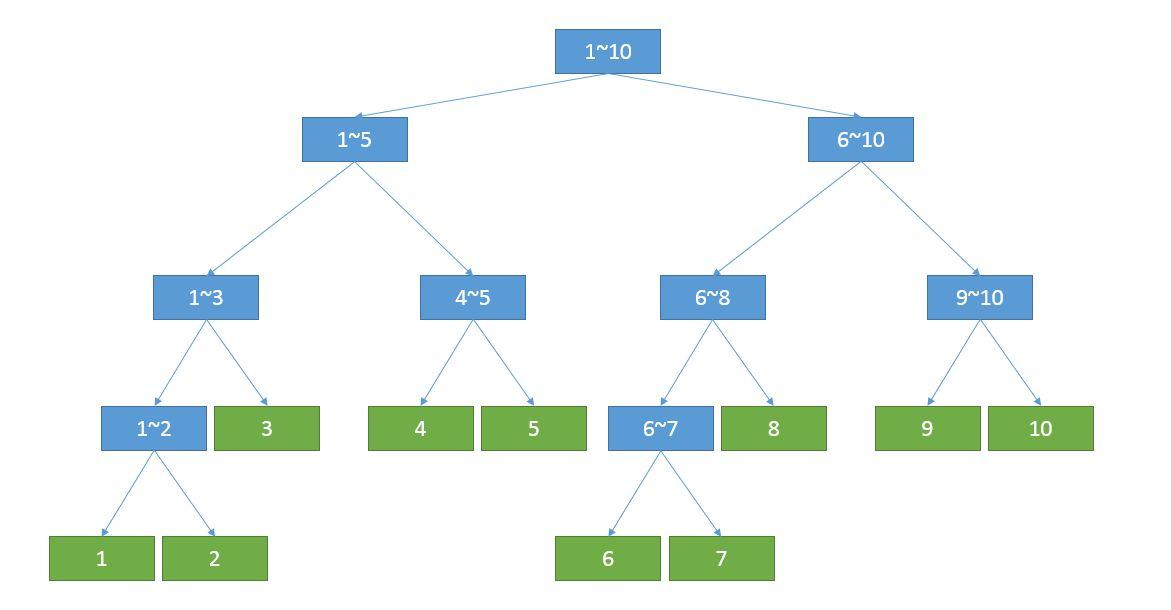
1.定义:线段树(Segment Tree)是一种二叉搜索树,它将一个区间划分成一些单元区间,每个单元区间对应线段树
中的一个叶结点。对于线段树中的每一个非叶子节点[a,b],它的左儿子表示的区间为[a,(a+b)/2],右儿子表示的区间为
[(a+b)/2,b]。因此线段树是满二叉树,最后的子节点数目为N,即整个线段区间的长度。使用线段树可以快速的查找某
一个节点在若干条线段中出现的次数,时间复杂度为O(logN)。而未优化的空间复杂度为2N,因此有时需要离散化让
空间压缩。
2.从一个小问题引出线段树
问题:在自然数,且所有的数不大于30000的范围内讨论一个问题:现在已知n条线段,把端点依次输入告诉你,然
后有m个询问,每个询问输入一个点,要求这个点在多少条线段上出现过;
基本解法(一)分析:最基本的解法当然就是读一个点,就把所有线段比一下,看看在不在线段中;每次询问都要
把n条线段查一次,那么m次询问,就要运算m*n次,复杂度就是O(m*n)道题m和n都是30000,那么计算量达到10^9;
而计算机1秒的计算量大约是10^8的数量级,所以这种方法无论怎么优化都是超时。因为n条线段是固定的,所以某种
程度上说每次都把n条线段查一遍有大量的重复和浪费;线段树就是可以解决这类问题的数据结构
线段树解题:
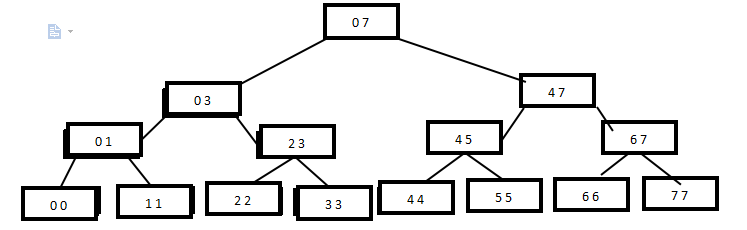
已知线段[2,5] [4,6] [0,7];求点2,4,7分别出现了多少次?
在[0,7]区间上建立一棵满二叉树:
每个节点用结构体:
struct line
{
int left,right;//左端点、右端点
int n;//记录这条线段出现了多少次,默认为0
}a[16];
//和堆类似,满二叉树的性质决定a[i]的左儿子是a[2*i]、右儿子是a[2*i+1];然后对于已知的线段依次进行插入操作:从树根开始调用递归函数insert
void insert(int s,int t,int step)//要插入的线段的左端点和右端点、以及当前线段树中的某条线段
{
if (s==a[step].left && t==a[step].right)
{
a[step].n++;//插入的线段匹配则此条线段的记录+1
return;//插入结束返回
}
if (a[step].left==a[step].right) return;//当前线段树的线段没有儿子,插入结束返回
int mid=(a[step].left+a[step].right)/2;
if (mid>=t) insert(s,t,step*2);//如果中点在t的右边,则应该插入到左儿子
else if (mid<t) insert(t,s,step*2+1);
else//否则,中点一定在s和t之间,把待插线段分成两半分别插到左右儿子里面
{
insert(s,mid,step*2);
insert(mid+1,t,step*2+1);
}
}
三条已知线段插入过程:
[2,5]
--[2,5]与【0,7】比较,分成两部分:[2,3]插到左儿子【0,3】,[4,5]插到右儿子【4,7】
--[2,3]与【0,3】比较,插到右儿子【2,3】;[4,5]和【4,7】比较,插到左儿子【4,5】
--[2,3]与【2,3】匹配,【2,3】记录+1;[4,5]与【4,5】匹配,【4,5】记录+1
[4,6]
--[4,6]与【0,7】比较,插到右儿子【4,7】
--[4,6]与【4,7】比较,分成两部分,[4,5]插到左儿子【4,5】;[6,6]插到右儿子【6,7】
--[4,5]与【4,5】匹配,【4,5】记录+1;[6,6]与【6,7】比较,插到左儿子【6,6】
--[6,6]与【6,6】匹配,【6,6】记录+1
[0,7]
--[0,7]与【0,7】匹配,【0,7】记录+1
插入过程结束,线段树上的记录如下(红色数字为每条线段的记录n):
询问操作和插入操作类似,也是递归过程,略
2——依次把【0,7】 【0,3】 【2,3】 【2,2】的记录n加起来,结果为2
4——依次把【0,7】 【4,7】 【4,5】 【4,4】的记录n加起来,结果为3
7——依次把【0,7】 【4,7】 【6,7】 【7,7】的记录n加起来,结果为1
不管是插入操作还是查询操作,每次操作的执行次数仅为树的深度——logN
建树有n次插入操作,n*logN,一次查询要logN,m次就是m*logN;总共复杂度O(n+m)*logN,这道题N不超过
30000,logN约等于14,所以计算量在10^5~10^6之间,比普通方法快了1000倍;
这道题是线段树最基本的操作,只用到了插入和查找;删除操作和插入类似,扩展功能的还有测度、连续段数等等,
在N数据范围很大的时候,依然可以用离散化的方法建树。
第二部分:
一 概述
线段树,类似区间树,它在各个节点保存一条线段(数组中的一段子数组),主要用于高效解决连续区间的动态查询问题,由于二叉结构的特性,它基本能保持每个操作的复杂度为O(logn)。
线段树的每个节点表示一个区间,子节点则分别表示父节点的左右半区间,例如父亲的区间是[a,b],那么(c=(a+b)/2)左儿子的区间是[a,c],右儿子的区间是[c+1,b]。
下面我们从一个经典的例子来了解线段树,问题描述如下:从数组arr[0...n-1]中查找某个数组某个区间内的最小值,其中数组大小固定,但是数组中的元素的值可以随时更新。
对这个问题一个简单的解法是:遍历数组区间找到最小值,时间复杂度是O(n),额外的空间复杂度O(1)。当数据量特别大,而查询操作很频繁的时候,耗时可能会不满足需求。
另一种解法:使用一个二维数组来保存提前计算好的区间[i,j]内的最小值,那么预处理时间为O(n^2),查询耗时O(1), 但是需要额外的O(n^2)空间,当数据量很大时,这个空间消耗是庞大的,而且当改变了数组中的某一个值时,更新二维数组中的最小值也很麻烦。
我们可以用线段树来解决这个问题:预处理耗时O(n),查询、更新操作O(logn),需要额外的空间O(n)。根据这个问题我们构造如下的二叉树
- 叶子节点是原始组数arr中的元素
- 非叶子节点代表它的所有子孙叶子节点所在区间的最小值
例如对于数组[2, 5, 1, 4, 9, 3]可以构造如下的二叉树(背景为白色表示叶子节点,非叶子节点的值是其对应数组区间内的最小值,例如根节点表示数组区间arr[0...5]内的最小值是1):
智能推荐
论文笔记《Knowledge Enhanced Contextual Word Representations》-程序员宅基地
文章浏览阅读3.8k次,点赞6次,收藏9次。Motivition作者的出发点有几个:尽管BERT这种预训练模型取得了state-of-art的成绩。但是、因为他们没有包含真实世界的实体,所以导致这些模型也很难覆盖真实世界的知识。没有实体没有知识怎么办呢?Knowledge bases、知识库有。知识库不仅拥有丰富的高质量、人类产生的知识,而且他们包含与原始文本中互补的信息,还能够编码事实性的知识。所以用知识库可以解决因不频繁出现但..._knowledge enhanced contextual word representations
百度地图 生成静态缩略图_百度地图 sdk 缩略图-程序员宅基地
文章浏览阅读296次。【代码】百度地图 生成静态缩略图。_百度地图 sdk 缩略图
使nginx支持pathinfo模式_nginx 支持pathinfo-程序员宅基地
文章浏览阅读259次。在将fastadmin部署到虚拟机中时,遇到如下问题:当访问登录页面时,页面进行不断的循环跳转重定向。解决方法是将nginx配置为支持pathinfo的模式。_nginx 支持pathinfo
ant design vue 列表List_vue3中ant design vue中的a-list组件如何获取点击每条数据的详情-程序员宅基地
文章浏览阅读2.6k次。<a-list item-layout="horizontal" :data-source="data"> <a-list-item slot="renderItem" slot-scope="item"> <a-list-item-meta :description="item.content" > <a slot="title" href="">{{ item.title }}</a&g_vue3中ant design vue中的a-list组件如何获取点击每条数据的详情
eclipse 与资源库同步时忽略多余文件的一种方法_与资源库同步时 怎么去除 .classpath-程序员宅基地
文章浏览阅读1.8k次。项目开发中在和服务器同步时,每次都看到一堆.class,.log,target等文件,这样很不舒服。解决方法:打开:window-->preferences-->team-->Ignored Resource-->Add Pattern 忽略文件夹:如忽略target文件夹,就Add Pattern,填入*/target/*忽略文件:如忽略.class类型的,直接填入 ._与资源库同步时 怎么去除 .classpath
VS2008 编译错误,生成后事件问题 Error 1 error PRJ0019: A tool returned an error code from “Performing Post-Build-程序员宅基地
文章浏览阅读966次。VS2008 bulid项目时提示错误:Error 1 error PRJ0019: A tool returned an error code from “Performing Post-Build Event”,应该是生成后事件的问题。解决方案:右键项目,属性,点击Post-Build-Event,在command Line编辑框里的路径加上英文双引号即可。........._a tool returned an error code
随便推点
使用js前端实现word、excel、pdf、ppt 在线预览解答_前端如何在线浏览excel-程序员宅基地
文章浏览阅读929次,点赞3次,收藏2次。JS,HTML5 VUE 等怎么实现在线预览支持多格式_前端如何在线浏览excel
vim查找字符串-全词匹配、不区分大小写_gvim 全字匹配查找-程序员宅基地
文章浏览阅读5.6w次,点赞13次,收藏43次。vim中查找字符串的时候一般有3中需求:普通查找命令模式下,按’/’或’?’,然后输入要查找的字符,Enter。/和?的区别是,一个向前(下)找,一个向后(上)。全词匹配如果你输入 “/int”,你也可能找到 “print”。 要找到以 “int” 结尾的单词,可以用: /int\> “\>” 是一个特殊的记号,表示只匹配单词末尾。类似地,”\<” 只匹配单词的开头。一次,要匹配一个_gvim 全字匹配查找
3090/3080显卡服务器docker中使用torch的.cuda()语句卡住卡死问题解决方法_cuda阻塞在docker中-程序员宅基地
文章浏览阅读4.6k次,点赞6次,收藏14次。30系列显卡docker+pytorch环境配置问题问题描述:项目组新进了一批3090显卡的服务器,尝试把之前部署在20系列显卡上的dorcker部署到新服务器上。之前的docker内部包含内容为:cuda10.1+pytorch1.3.0。直接将老镜像打包导入新服务器之后,python中运行如下语句:>>import torch>>a=torch.zeros(1)>>a=a.cuda()之后程序就一直卡死了,没有任何报错和警告。在尝试跑模型代码时也会存在各_cuda阻塞在docker中
Windows+IDEA本地调试Apache Kylin3.1.0源码调试-Coordinator(简单易操作版)_kylin-app 本地调试-程序员宅基地
文章浏览阅读700次。Windows+ IEDA 本地调试Apache Kylin3.1.0源码-Coordinator_kylin-app 本地调试
重写org.springframework.beans.BeanUtils的copyProperties(Object source,Object target)方法 从model复制属性到pojo中_beanutils.copyproperties重写-程序员宅基地
文章浏览阅读3.3k次。重写_beanutils.copyproperties重写
定时任务实现的关键DelayQueue延迟队列_delayqueue队列中数据时间一致怎么先后执行-程序员宅基地
文章浏览阅读461次。之前学习定时任务线程池(ScheduledThreadPoolExecutor)时发现它主要依赖线程池和它的静态内部类DelayedWorkQueue实现。而DelayedWorkQueue就是一种延迟队列,今天学习是并发包提供的延迟队列(DelayQueue)。延迟队列说明延迟队列提供的功能是在指定时间点才能获取队列元素的功能,队列最前面的元素是最优先执行的元素。列举一下使用场景可能能够更加好理解,比如缓存系统的设计,缓存中的对象,指定了过期时间,到了过期时间就需要从缓存中移出;在比如任务调度系_delayqueue队列中数据时间一致怎么先后执行