【机器学习笔记37】模糊聚类分析(基于最大生成树)_模糊聚类分析例题-程序员宅基地
技术标签: 模糊数学 聚类 机器学习 机器学习笔记 最大生成树 人工智能
【参考资料】
【1】《模式识别与智能计算的MATLAB技术实现》
【2】《模糊数学方法及其应用》
【3】https://baike.baidu.com/item/Kruskal/10242089?fr=aladdin
1. 模糊关系的矩阵定义
模糊集定义及基础信息,参考之前笔记《模糊数学笔记-模糊集》
1.1 模糊关系
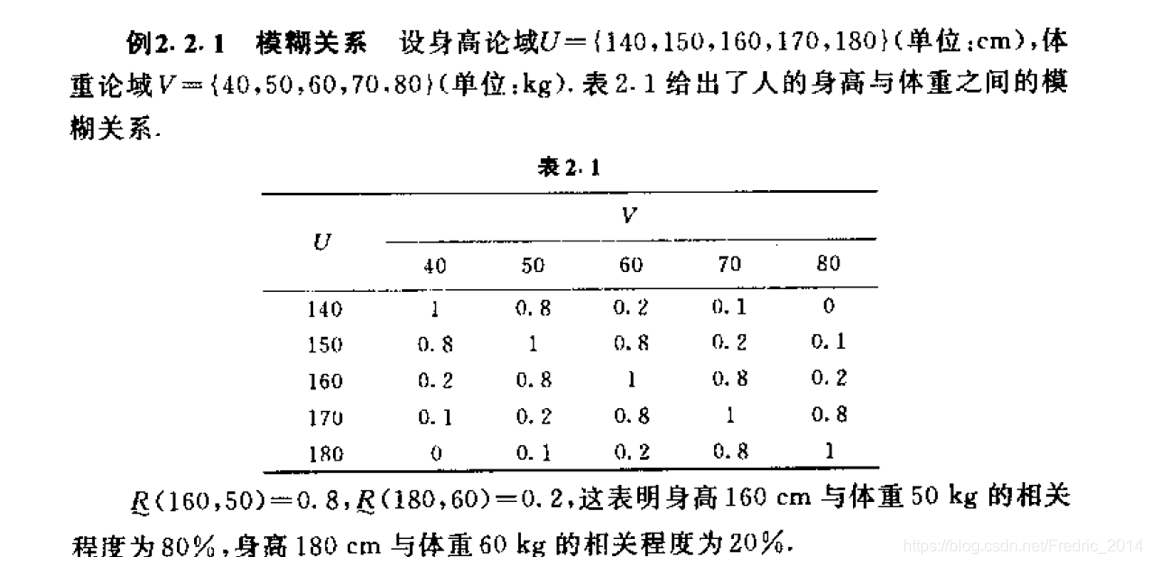
定义: 设论域U,V,称 U × V U \times V U×V的一个模糊子集 R ∼ ∈ F ( U × V ) \underset{\sim}{R} \in F(U \times V) ∼R∈F(U×V)为U到V的模糊关系。其隶属函数映射为:
U R : U × V → [ 0 , 1 ] U_R: U \times V \to [0, 1] UR:U×V→[0,1] 其隶属度 R ∼ ( x , y ) \underset{\sim}{R}(x,y) ∼R(x,y)称为(x,y)关于模糊关系 R ∼ \underset{\sim}{R} ∼R的相关程度。
举例:
1.2 模糊矩阵
我们可以将上述关系用模糊矩阵来表述,有点类似马儿可夫随机过程里定义状态转移矩阵
定义矩阵 R = ( r i j ) m × n R=(r_{ij})_{m \times n} R=(rij)m×n为模糊矩阵,例如:
[ 1 0 0.1 0.5 0.7 0.3 ] \begin{bmatrix} 1 & 0 & 0.1 \\ 0.5 & 0.7 & 0.3 \end{bmatrix} [10.500.70.10.3],这里 r i j ∈ [ 0 , 1 ] r_{ij} \in [0, 1] rij∈[0,1]
这里比较主要的是模糊矩阵的合成运算,如下:
定义:设 A = ( a i j ) m × t A=(a_{ij})_{m \times t} A=(aij)m×t, B = ( b i j ) t × n B=(b_{ij})_{t \times n} B=(bij)t×n称模糊矩阵 A ∘ B = ( c i j ) m × n A \circ B = (c_{ij})_{m \times n} A∘B=(cij)m×n
其中$ (c_{ij}) = {\lor}{t = 1}^s(a{it} \land b_{tj}) $
这里和矩阵乘法类似,只是在具体的运算中原先的元素乘元素编程取最小值,原先的乘积相加变为求最大值。 举例:
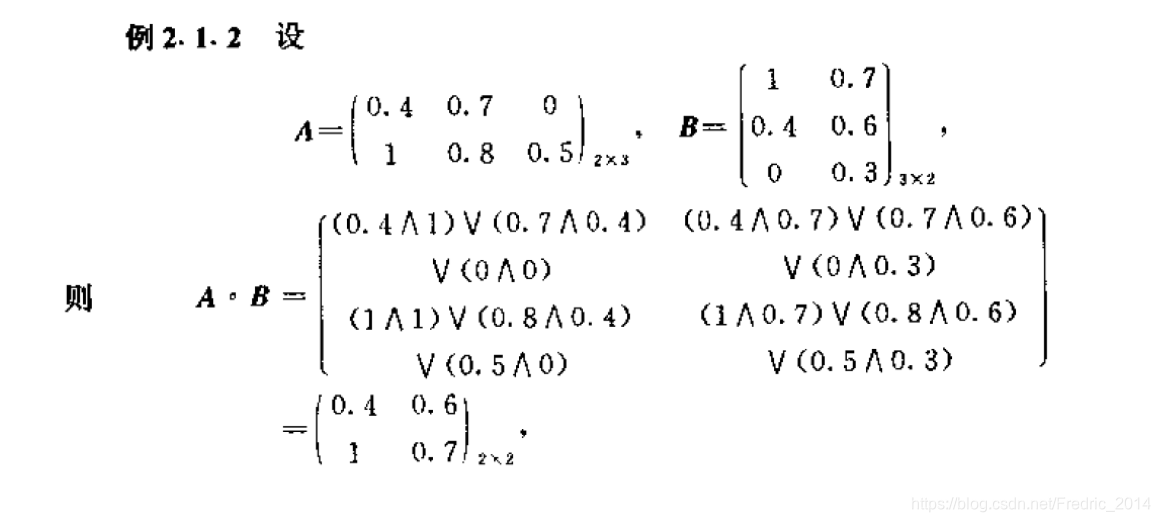
其次我们定义模糊矩阵的 λ \lambda λ截距矩阵,这个定义比较简单,矩阵中的每个元素大于 λ \lambda λ则为1,否则为0。举例如下:

2. 模糊关系的聚类分析
2.1 基于模糊矩阵的等价关系
如果模糊矩阵满足等价关系的三个要素,即:
- 自反性: r i j = 1 r_{ij} = 1 rij=1
- 对称性: r i j = r j i r_{ij} = r_{ji} rij=rji
- 传递性: R ∘ R ≤ R R \circ R \le R R∘R≤R
即( r i j ) ≥ ∨ t = 1 s ( r i t ∧ r t j ) (r_{ij}) \ge {\lor}_{t = 1}^s(r_{it} \land r_{tj}) (rij)≥∨t=1s(rit∧rtj)
这里有一点不理解,为什么传递性中是小于等于而非直接等于?
举例:
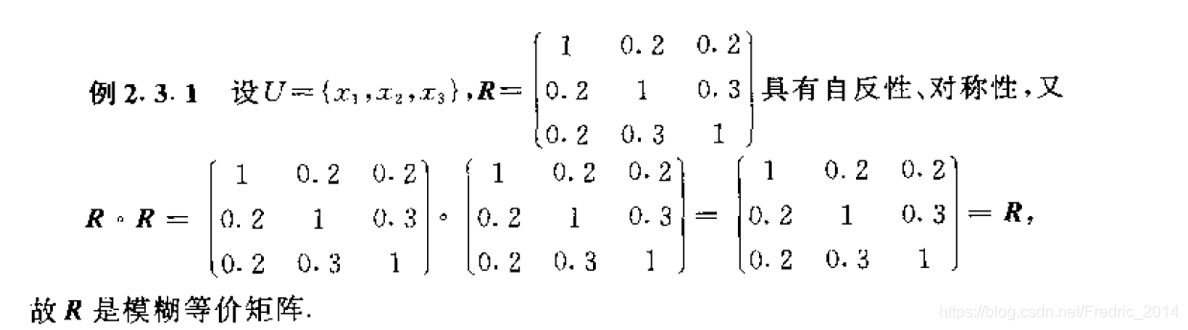
2.2 基于模糊矩阵的分类
由于等价关系代表着集合上的一个分类,因此在模糊聚类中,我们对模糊矩阵取不同的 λ \lambda λ截距,就可以取不同的分类。

3. 模糊聚类的算法步骤
第一步建立原始数据矩阵:
存在n个被分类对象,每个对象存在m个属性,则有:
[ x 11 x 12 ⋯ x 1 m x 21 x 22 ⋯ x 2 m ⋯ ⋯ ⋯ ⋯ x n 1 x n 2 ⋯ x n m ] \begin{bmatrix} x_{11} & x_{12} & \cdots & x_{1m}\\ x_{21} & x_{22} & \cdots & x_{2m}\\ \cdots & \cdots & \cdots & \cdots\\ x_{n1} & x_{n2} & \cdots & x_{nm} \end{bmatrix} ⎣⎢⎢⎡x11x21⋯xn1x12x22⋯xn2⋯⋯⋯⋯x1mx2m⋯xnm⎦⎥⎥⎤,同时将数据归一化到[0,1]之间。
第二步建立模糊相似矩阵:
对第一步建立的数据矩阵,其元素 x i x_i xi和 x j x_j xj建立一个相似矩阵。其中每一个元素 r i j r_{ij} rij代表 x i x_i xi和 x j x_j xj。这里的相似度可以用多种方式做,比如数量积、相关系数等。
比如数量积定义:
r i j = { 1 , i = j 1 M ∑ k = 1 m x i k . x j k , i ≠ j r_{ij}= \begin{cases} 1, & i = j \\ \dfrac{1}{M} \sum\limits_{k=1}^{m}x_{ik}.x_{jk}, & i \ne j \end{cases} rij=⎩⎨⎧1,M1k=1∑mxik.xjk,i=ji̸=j
这里 M = m a x ( ∑ k = 1 m x i k . x j k ) M = max(\sum\limits_{k=1}^{m}x_{ik}.x_{jk}) M=max(k=1∑mxik.xjk)
这里的结果也归一化到[0,1]之间
第三步聚类操作:
这里举例为最大树法。

这里用的就是最大生成树Kruskal算法
4. 程序实现
# -*- coding: utf-8 -*-
import numpy as np
import sklearn.datasets as ds
import matplotlib.pyplot as plt
import random
import math
import operator
SAMPLE_NUM = 200 #样本数量
FEATURE_NUM = 2 #每个样本的特征数量
CLASS_NUM = 2 #分类数量
#1. 初始化测试数据
sample, y = ds.make_blobs(SAMPLE_NUM, n_features=FEATURE_NUM, centers=CLASS_NUM, random_state=3)
sim_array = [[0 for col in range(SAMPLE_NUM)] for row in range(SAMPLE_NUM)]
tree_node = [] #选择的节点
path_node = [] #路径
value_node = [] #存储路径对应的值
def _build_kruskal_tree():
#kruskal每次筛选与当前已选区域联通的点,将满足要求最好的点加入已选区域
tree_node.append(0)
while len(tree_node) < SAMPLE_NUM :
tmp_sum = 0
tmp_set = (0,0)
tmp_node = 0
for node in tree_node:
for i in range(0, SAMPLE_NUM):
if node == i:
continue
else:
if i in tree_node:
continue
else:
#计算距离
if sim_array[node][i] > tmp_sum:
tmp_sum = sim_array[node][i]
tmp_set = (node, i)
tmp_node = i
path_node.append(tmp_set)
tree_node.append(tmp_node)
value_node.append((len(path_node), tmp_sum))
def _do_fuzzy_cluster():
#2. 构造相似矩阵
max = 0
for i in range(0, SAMPLE_NUM):
for j in range(0, SAMPLE_NUM):
if i == j:
sim_array[i][j] = 1
else:
tmp = 0
for k in range(0, FEATURE_NUM):
tmp += sample[i][k] * sample[j][k]
sim_array[i][j] = tmp
if tmp > max:
max = tmp
for i in range(0, SAMPLE_NUM):
for j in range(0, SAMPLE_NUM):
if i != j:
sim_array[i][j] = sim_array[i][j]/max
#3. 构造最大树
_build_kruskal_tree()
#4. 聚类划分并显示
#根据最大生成树来进行分类
value_node.sort(key= operator.itemgetter(1))
gamma = value_node[int(len(value_node)/2)][1]
#根据这个gamma值分开
y_pre = [0 for col in range(SAMPLE_NUM)]
for i in range(0, SAMPLE_NUM - 1):
start = path_node[i][0]
end = path_node[i][1]
if value_node[i][1] > gamma:
y_pre[start] = 1
y_pre[end] = 1
else:
y_pre[start] = 0
y_pre[end] = 0
#print(np.array(y_pre))
#print(y)
#显示
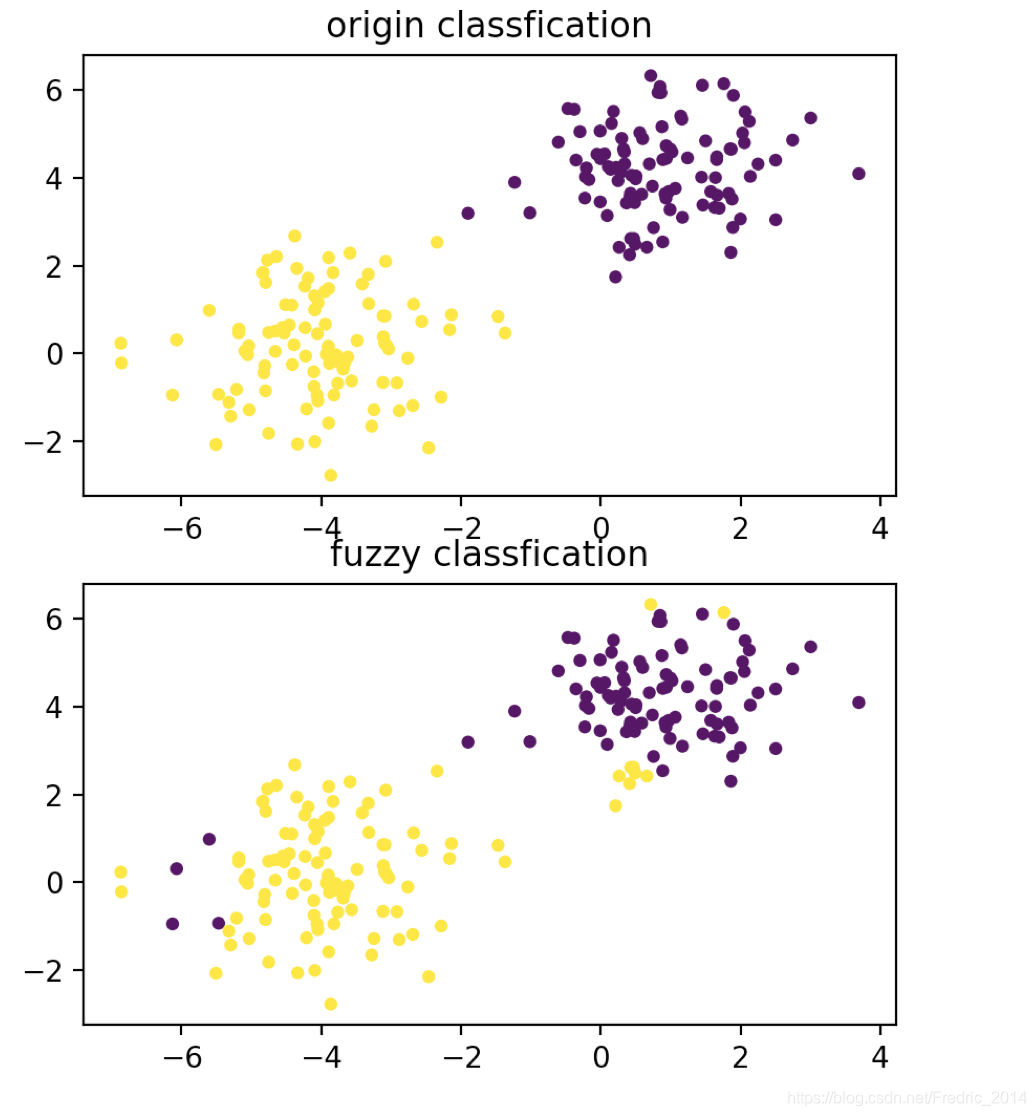
plt.figure(figsize=(5, 6), facecolor='w')
plt.subplot(211)
plt.title('origin classfication')
plt.scatter(sample[:, 0], sample[:, 1], c=y, s=20, edgecolors='none')
plt.subplot(212)
plt.title('fuzzy classfication')
plt.scatter(sample[:, 0], sample[:, 1], c=np.array(y_pre), s=20, edgecolors='none')
plt.show()
"""
说明:
模糊聚类的代码实现,基于最大树算法,针对笔记《模糊聚类分析》
作者:fredric
日期:2018-12-23
"""
if __name__ == "__main__":
_do_fuzzy_cluster()
智能推荐
Sandboxie v5.45.2正式版 系统安全工具_sandboxie系统安全工具-程序员宅基地
文章浏览阅读141次。简介:菜鸟高手裸奔工具沙盘Sandboxie是一款国外著名的系统安全工具,它可以让选定程序在安全的隔离环境下运行,只要在此环境中运行的软件,浏览器或注册表信息等都可以完整的进行清空,不留一点痕迹。同时可以防御些带有木马或者病毒的恶意网站,对于经常测试软件或者不放心的软件,可放心在沙盘里面运行!下载地址:http://www.bytepan.com/J7BwpqQdKzR..._sandboxie系统安全工具
Mac技巧|如何在 MacBook上设置一位数登录密码-程序员宅基地
文章浏览阅读230次,点赞4次,收藏5次。Mac老用户都知道之前的老版本系统是可以设置一位数登陆密码的,但是更新到10.14以后就不可以了,今天就教大家怎么在新版本下设置Mac一位数登陆密码。
chatgpt中的强化学习 PPO_chatgpt使用的强化学习-程序员宅基地
文章浏览阅读3.4k次。本该到此结束,但是上述实现的时候其实是把生成的每一步的奖励都使用统一的句子级reward,但该代码其实也额外按照每个token来计算奖励值的,为了获取每个token的奖励,我们在生成模型的隐层表示上,多加一个线性层,映射到一维,作为每个状态的预测奖励值。类似的,在文本生成中我们也可以用蒙特卡洛方法来估计一个模型的状态价值。假如我们只采样到了s1和s2,没有采样到s3,由于7和3都是正向奖励,s1和s2的训练后生成的概率都会变大,且s1的概率变的更大,这看似合理,但是s3是未参与训练的,它的概率反而减小了。_chatgpt使用的强化学习
获取不规则多边形中心点_truf计算重心-程序员宅基地
文章浏览阅读433次,点赞10次,收藏8次。尝试了3种方法,都失败了!_truf计算重心
HDU 1950最长上升子序列 学习nlogn_poj 1631 hdu 1950为啥是最长上升子序列-程序员宅基地
文章浏览阅读406次。学习LIS_poj 1631 hdu 1950为啥是最长上升子序列
kubernetes===》二进制安装_sed -ie 's#image.*#image: ${ epic_image_fullname }-程序员宅基地
文章浏览阅读550次。一、节点规划主机名称IP域名解析k8s-m-01192.168.12.51m1k8s-m-02192.168.12.52m2k8s-m-03192.168.12.53m3k8s-n-01192.168.12.54n1k8s-n-02192.168.12.55n2k8s-m-vip192.168.12.56vip二、插件规划#1.master节点规划kube-apiserverkube-controller-manage_sed -ie 's#image.*#image: ${ epic_image_fullname }#g
随便推点
UAC绕过提权_uac白名单 提权-程序员宅基地
文章浏览阅读106次。UAC绕过提权_uac白名单 提权
Linux一键部署OpenVPN脚本-程序员宅基地
文章浏览阅读664次,点赞7次,收藏12次。每次架设OpenVPN Server就很痛苦,步骤太多,会出错的地方也多,基本很少一次性成功的。
头文件的相互包含问题_多个头文件相互包含-程序员宅基地
文章浏览阅读397次。 今天看了继承以及派生类,并且运行了教程中的一个实例,但是仍然有好多坑。主要如下:建立了一个基类bClass以及由基类bClass派生的一个dClass,并且建立两个头文件.h分别申明这两个类,在cpp程序中进行运行来检验。具体程序如下:#ifndef ITEM_BASE//为避免类重复定义,需要在头文件的开头和结尾加上如这个所示 #define ITEM_BASEclass bClass..._多个头文件相互包含
python -- PyQt5(designer)安装详细教程-程序员宅基地
文章浏览阅读1.3w次,点赞19次,收藏88次。PyQt5安装详细教程,安装步骤很详细
微信小程序scroll-view去除滚动条-程序员宅基地
文章浏览阅读154次。官方文档:https://developers.weixin.qq.com/miniprogram/dev/component/scroll-view.html。_scroll-view去除滚动条
POJ-3233 Matrix Power Series 矩阵A^1+A^2+A^3...求和转化-程序员宅基地
文章浏览阅读146次。S(k)=A^1+A^2...+A^k.保利求解就超时了,我们考虑一下当k为偶数的情况,A^1+A^2+A^3+A^4...+A^k,取其中前一半A^1+A^2...A^k/2,后一半提取公共矩阵A^k/2后可以发现也是前一半A^1+A^2...A^k/2。因此我们可以考虑只算其中一半,然后A^k/2用矩阵快速幂处理。对于k为奇数,只要转化为k-1+A^k即可。n为矩阵数量,m为矩阵..._a^1 a^2 ... a^k