MapReduce之GroupingComparator分组(辅助排序、二次排序)_mapreduce groupingcomparator-程序员宅基地
技术标签: java mapreduce Hadoop hadoop 大数据
指对Reduce阶段的数据根据某一个或几个字段进行分组。
案例
需求
有如下订单数据
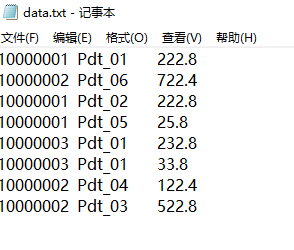
现在需要找出每一个订单中最贵的商品,如图

需求分析
-
利用“订单id和成交金额”作为
key,可以将Map阶段读取到的所有订单数据先按照订单id(升降序都可以),再按照acount(降序)排序,发送到Reduce。 -
在Reduce端利用
groupingComparator将订单id相同的kv聚合成组,然后取第一个成交金额即是最大值(若有多个成交金额并排第一,则都输出)。 -
Mapper阶段主要做三件事:
keyin-valuein
map()
keyout-valueout -
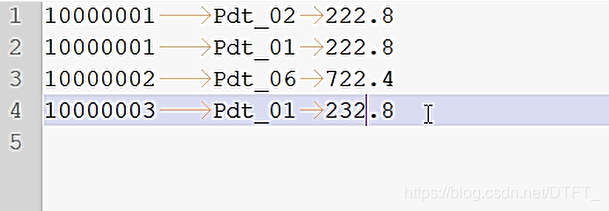
期待shuffle之后的数据:
10000001 Pdt_02 222.8
10000001 Pdt_01 222.8
10000001 Pdt_05 25.810000002 Pdt_06 722.4
10000002 Pdt_03 522.8
10000002 Pdt_04 122.410000003 Pdt_01 232.8
10000003 Pdt_01 33.8 -
Reducer阶段主要做三件事:
keyin-valuein
reduce()
keyout-valueout -
进入Reduce需要考虑的事
- 获取分组比较器,如果没设置默认使用MapTask排序时key的比较器
- 默认的比较器比较策略不符合要求,它会将orderId一样且acount一样的记录才认为是一组的
- 自定义分组比较器,只按照orderId进行对比,只要OrderId一样,认为key相等,这样可以将orderId相同的分到一个组!
在组内去第一个最大的即可
编写程序
利用“订单id和成交金额”作为key,所以把每一行记录封装为bean。由于需要比较ID,所以实现了WritableComparable接口
OrderBean.java
public class OrderBean implements WritableComparable<OrderBean>{
private String orderId;
private String pId;
private Double acount;
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public String getpId() {
return pId;
}
public void setpId(String pId) {
this.pId = pId;
}
public Double getAcount() {
return acount;
}
public void setAcount(Double acount) {
this.acount = acount;
}
public OrderBean() {
}
@Override
public String toString() {
return orderId + "\t" + pId + "\t" + acount ;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(orderId);
out.writeUTF(pId);
out.writeDouble(acount);
}
@Override
public void readFields(DataInput in) throws IOException {
orderId=in.readUTF();
pId=in.readUTF();
acount=in.readDouble();
}
// 二次排序,先按照orderid排序(升降序都可以),再按照acount(降序)排序
@Override
public int compareTo(OrderBean o) {
//先按照orderid排序升序排序
int result=this.orderId.compareTo(o.getOrderId());
if (result==0) {
//订单ID相同,就比较成交金额的大小
//再按照acount(降序)排序
result=-this.acount.compareTo(o.getAcount());
}
return result;
}
}
自定义比较器,可以通过两种方法:
- 继承
WritableCompartor - 实现
RawComparator
MyGroupingComparator.java
//实现RawComparator
public class MyGroupingComparator implements RawComparator<OrderBean>{
private OrderBean key1=new OrderBean();
private OrderBean key2=new OrderBean();
private DataInputBuffer buffer=new DataInputBuffer();
@Override
public int compare(OrderBean o1, OrderBean o2) {
return o1.getOrderId().compareTo(o2.getOrderId());
}
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
buffer.reset(b1, s1, l1); // parse key1
key1.readFields(buffer);
buffer.reset(b2, s2, l2); // parse key2
key2.readFields(buffer);
buffer.reset(null, 0, 0); // clean up reference
} catch (IOException e) {
throw new RuntimeException(e);
}
return compare(key1, key2);
}
}
MyGroupingComparator2.java
//继承WritableCompartor
public class MyGroupingComparator2 extends WritableComparator{
public MyGroupingComparator2() {
super(OrderBean.class,null,true);
}
public int compare(WritableComparable a, WritableComparable b) {
OrderBean o1=(OrderBean) a;
OrderBean o2=(OrderBean) b;
return o1.getOrderId().compareTo(o2.getOrderId());
}
}
OrderMapper.java
public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable>{
private OrderBean out_key=new OrderBean();
private NullWritable out_value=NullWritable.get();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, OrderBean, NullWritable>.Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split("\t");
out_key.setOrderId(words[0]);
out_key.setpId(words[1]);
out_key.setAcount(Double.parseDouble(words[2]));
context.write(out_key, out_value);
}
}
OrderReducer.java
public class OrderReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable>{
/*
* OrderBean key-NullWritable nullWritable在reducer工作期间,
* 只会实例化一个key-value的对象!
* 每次调用迭代器迭代下个记录时,使用反序列化器从文件中或内存中读取下一个key-value数据的值,
* 封装到之前OrderBean key-NullWritable nullWritable在reducer的属性中
*/
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values,
Reducer<OrderBean, NullWritable, OrderBean, NullWritable>.Context context)
throws IOException, InterruptedException {
Double maxAcount = key.getAcount();
for (NullWritable nullWritable : values) {
if (!key.getAcount().equals(maxAcount)) {
break;
}
//复合条件的记录
context.write(key, nullWritable);
}
}
}
OrderBeanDriver.java
public class OrderBeanDriver {
public static void main(String[] args) throws Exception {
Path inputPath=new Path("E:\\mrinput\\groupcomparator");
Path outputPath=new Path("e:/mroutput/groupcomparator");
//作为整个Job的配置
Configuration conf = new Configuration();
//保证输出目录不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// ①创建Job
Job job = Job.getInstance(conf);
// ②设置Job
// 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class);
// Job需要根据Mapper和Reducer输出的Key-value类型准备序列化器,通过序列化器对输出的key-value进行序列化和反序列化
// 如果Mapper和Reducer输出的Key-value类型一致,直接设置Job最终的输出类型
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
// 设置输入目录和输出目录
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 设置自定义的分组比较器
job.setGroupingComparatorClass(MyGroupingComparator2.class);
// ③运行Job
job.waitForCompletion(true);
}
}
输出结果
智能推荐
linux_sed/grep 匹配不起作用/CRLF导致shell脚本无法正常运行_linux cat有输出 grep无输出-程序员宅基地
文章浏览阅读2.8k次。文章目录linux grep/sed 匹配不起作用匹配异常案例生成引发问题的powershell脚本cat 的查看选项关于控制符/空白字符/非打印字符显示引发问题的文本文件表面内容实际内容正常内容总结可能的解决办法linux grep/sed 匹配不起作用在某些情况下,sed和grep的可能无法正常工作其中,我认为最大的可能就是编码或者控制字符的问题匹配异常案例我在Windows端用powershell的函数创建了一个包含多个时间戳的文件生成引发问题的powershell脚本Write_linux cat有输出 grep无输出
SVG 技术简介和应用场景分析_svg和pcs的区别-程序员宅基地
文章浏览阅读713次。简介应用场景绘图滤镜动画_svg和pcs的区别
$ref的用法_\$ref-程序员宅基地
文章浏览阅读1.6k次。this.$ref的用法<div id="app"><input type="text" ref="input1"/><button @click="add">添加</button></div><script>new Vue({el: "#app",methods:{add:function(){this.$refs.input1.value ="22"; //this.$refs.input1 _\$ref
Linux日志切割神器Logrotate_logrotate切割日志的优缺点-程序员宅基地
文章浏览阅读823次。logrotate程序是一个日志文件管理工具。用于分割日志文件,删除旧的日志文件,并创建新的日志文件,起到“转储”作用。可以节省磁盘空间。下面就对logrotate日志轮转操作做一梳理记录。为什么要切割日志文件?大文件被切割后,访问速度大大加快 按天切割后,方便定位程序问题 删除旧的日志文件(比如2个月之前的),可以节省磁盘空间1、配置文件介绍Linux系统默认安装logrotate工具,它默认的配置文件在:/etc/logrotate.conf/etc/logrotate.d.._logrotate切割日志的优缺点
嵌入式入门 -第1章 学嵌入式从STM32开始-程序员宅基地
文章浏览阅读352次。1.1 STM32简介ARM公司简介ARM是Advanced RISC Machines的缩写,它是一家微处理器行业的知名企业,该企业设计了大量高性能、廉价、耗能低的RISC (精简指令集)处理器。公司的特点是只设计芯片,而不生产。它将技术授权给世界上许多著名的半导体、软件和OEM厂商,并提供服务。图1-1ARM(Advanced RISC Machines)有3..._stm嵌入式精髓
caffe源码解读(11)-triplet_loss_layer.cpp_三元组损失 caffe-程序员宅基地
文章浏览阅读500次。定义TripletLoss" role="presentation">TripletLossTripletLossTriplet Loss 的提出,是在这篇论文中——FaceNet: A Unified Embedding for Face Recognition and Clustering,论文中对TripletLoss" role="presentation">TripletLossT_三元组损失 caffe
随便推点
ABySS使用文档_abyssorangemix2 安装-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏2次。作者:龙炎联系邮箱:[email protected]时间:2016/07/25 一.ABySS的功能分别为: 组装paired-end库(paired-endlibrary),组装多个库(multiplelibraries), 组装长距离的mate-pair库(Long-distance mate-pair libraries),Resc_abyssorangemix2 安装
关于矩阵的编程题(C语言版,持续更新~~~~~~)_c语言普通矩阵"。请你帮忙他编程构造如下的普通矩阵(规则参看样例)。输入一个正整-程序员宅基地
文章浏览阅读2.4k次,点赞6次,收藏17次。1、矩阵对角线求和(分别求出主对角线和副对角线元素的和)2、矩阵对角线求和(主对角线和副对角线元素总和)3、4、第1题的思路:这里通过使用二维数组分别求出矩阵主对角线和副对角线元素的和。本题以三阶矩阵为例。在线性代数中,矩阵的下标是从1开始,例如a[1][1]表示第一行第一列的元素。但是如果在使用二维数组的情况下,矩阵的下标是从0开始的a[0][0]表示第一行第一列的元素。a11主对角线中ij副对角线,从右上到左下,通过观察我们可以发现在3*3矩阵中,在线性代数中副对角线上的元素行列坐标相_c语言普通矩阵"。请你帮忙他编程构造如下的普通矩阵(规则参看样例)。输入一个正整
2.STM32F427llHX(大疆A板) 点亮小灯(库函数版本)_stm32f427引脚图-程序员宅基地
文章浏览阅读955次。基于空白模板点亮小灯1.在Template文件夹中新建HARDWARE文件夹2.在HARDWARE文件夹中新建LED文件夹3.从正点原子实验1中复制led.c和led.h到LED文件夹中4.右键点击 Template,选择 Manage Project Items,在 Groups 一栏添加HARDWARE,往 Group 里面添加我们需要的文件:led.c5.添加..\HARDWARE\LED 头文件路径编译结果下载到板子发现小灯不亮原理图led.c中设置引脚是f407的,需_stm32f427引脚图
HDU DNA Sorting (树状数组求逆序对)-程序员宅基地
文章浏览阅读329次。这题就是求逆序对然后根据逆序对大小排序暴力可解!我选择的是树状数组,这题如果变种,数据过大,或者需要离散化,暴力就不好解决了离散化树状数组这题浪费挺长时间的,主要是t数组忘记清0.。导致后面的数据全部错误#include#include#include#include#include#include#includeusing namespace st_hdu dna sorting
Qt:基于Qt开发的轻量级HTTP/HTTPS服务器_qt http服务端地址怎么设置-程序员宅基地
文章浏览阅读3.5w次,点赞24次,收藏93次。JQHttpServer是基于Qt开发的轻量级HTTP服务器,目前支持GET和POST两个协议。底层有TcpSocket和LocalSocket两个版本,方便使用。用到的Qt库有:corenetworkconcurrenttestlib(测试用,运行不需要)理论上可以部署到任何Qt支持的平台上。推荐使用Linux系统或者Unix系统,因为在5.7后,Qt更换了Unix相关系统的底层模型,从_qt http服务端地址怎么设置
V4L2官方开发文档中文版_v4l2官方文档-程序员宅基地
文章浏览阅读1.1k次。下面的文档摘自高通源码的kernel\Documentation\zh_CN\video4linux\目录下的v4l2-framework.txt文档,如有侵权请相告,会及时处理。Chinese translated version of Documentation/video4linux/v4l2-framework.txtIf you have any comment or updat..._v4l2官方文档